PyVistaデータモデル#
このセクションでは,PyVistaフレームワークを使って,スクラッチからメッシュを作成する方法や,基礎となるVTKデータモデルを利用する方法を詳しく説明します. 私たちの 例 の多くは,単にファイルからデータを読み込むだけで,メッシュを構築したり,データセット内にデータを配置する方法を説明していません.
注釈
以下のドキュメントセクションはVTKを参照していますが,VTKの知識を必要とするものではありません. VTKとの詳細な比較や,VTKのPythonバインディングのために書かれたコードをPyVistaに翻訳したい方は, VTKからPyVistaへの移行 を参照してください.
APIのより一般的な説明については, メッシュとは? をご覧ください.
PyVistaデータセット#
VTKやPyVistaでデータを可視化するには,2つの情報が必要です.空間内の位置や値を表すデータのジオメトリと,データセット内の点が互いにどのように接続されているかを表すトポロジです.
一番上のレベルには vtkDataObject があります.これはジオメトリやトポロジーを持たない,単なるデータの "塊" です.これには vtkFieldData の配列が含まれます.その下にあるのが vtkDataSet で,これは vtkDataObject にジオメトリやトポロジを追加するものです.データセット内の全ての点やセルには特定の値が関連付けられている.これらの値は空間に配置され,接続されなければならないので, vtkDataArray クラスに保持され,これは単なるヒープ上のメモリバッファです.PyVistaでは,99%の場合, vtkDataObject オブジェクトではなく, vtkDataSet オブジェクトを操作します.PyVista は VTK と同じデータ型を使用しますが,使いやすくするために,よりpythonicな方法で構造化しています.
VTKがどのようにデータを構成しているかの背景を知りたい方は, Introduction to VTK in Python by Kitware や, Kitware's GitHub site に掲載されている多数のコード例をご覧ください.VTKで実装されている3Dモデリング全般に関連する数学的概念の優れた入門書は,Carnegie Mellon大学のKeenan Crane教授による Discrete Differential Geometry YouTube Series です.ここで紹介されている概念は,データセットがVTKのようなライブラリでどのように構造化されているかについての理解を深めるのに役立ちます.
最も基本的なレベルでは,すべての PyVista ジオメトリクラスは, データセット クラスを継承しています.データセットは,ジオメトリ,トポロジー,そして,ポイント,セル,フィールドアレイの形でジオメトリを記述する属性を持っています.
PyVistaのジオメトリは,点とセルで表現されます. 例えば, PolyData の中の1つのセルを考えてみましょう.
これらの点の空間上の位置を記述する方法が必要ですが,上で行ったように値そのものを表現することには限界があります(インデックスを持つ配列のリスト).VTKには(そしてPyVistaにも)異なるデータ形状を表す複数のクラスがあります.最も重要なデータセットクラスを以下に示します.

ここでは,上記のデータセットを,最も複雑なもの(5)から最も複雑でないもの(1)の順に並べています.つまり,どのデータセットも UnstructuredGrid として表現できますが,個々の点やセルを考慮しなければならないため, UnstructuredGrid クラスは最も多くのメモリを消費します.一方, vtkImageData (ImageData) は一様な間隔で配置されているので,いくつかの整数や浮動小数点数で形状を表現することができ,格納するメモリの量は最も少なくて済みます.
これは, PolyData や UnstructuredGrid では,ポイント,やセルを明示的に定義する必要があるからです. ImageData などの他のデータタイプでは,セル(さらにはポイント)はグリッドの次元性に基づいた創発的なプロパティとして定義されます.
実際には, PolyData で表される最も単純なサーフェスを作成してみましょう.まず,点を定義する必要があります.
PyVistaにおける点と配列#
PyVistaでは,様々な方法で点を作成することができますが,ここでは,いずれかの方法で効率的に点の配列を作成する方法を紹介します.
VTK配列のラッピング
numpy.ndarrayの使用または,単に
listを使うこともできます.
PyVistaでは,これら3つのアプローチに対応したPythonicメソッドを提供していますので,最も効率的な方法を選択することができます.VTK APIに慣れている場合は,VTK配列をラップすることもできますが, numpy.ndarray を使う方が便利で,Pythonのループ処理のオーバーヘッドを避けることができるでしょう.
VTK配列のラッピング#
3角形の点を定義してみましょう.VTKのAPIを使えば,このようなことができます.
>>> import vtk
>>> vtk_array = vtk.vtkDoubleArray()
>>> vtk_array.SetNumberOfComponents(3)
>>> vtk_array.SetNumberOfValues(9)
>>> vtk_array.SetValue(0, 0)
>>> vtk_array.SetValue(1, 0)
>>> vtk_array.SetValue(2, 0)
>>> vtk_array.SetValue(3, 1)
>>> vtk_array.SetValue(4, 0)
>>> vtk_array.SetValue(5, 0)
>>> vtk_array.SetValue(6, 0.5)
>>> vtk_array.SetValue(7, 0.667)
>>> vtk_array.SetValue(8, 0)
>>> print(vtk_array)
vtkDoubleArray (0x564f879439e0)
Debug: Off
Modified Time: 81
Reference Count: 1
Registered Events: (none)
Name: (none)
Data type: double
Size: 9
MaxId: 8
NumberOfComponents: 3
Information: 0
Name: (none)
Number Of Components: 3
Number Of Tuples: 3
Size: 9
MaxId: 8
LookupTable: (none)
PyVistaでは, vtkDataArray クラスから直接オブジェクトを作成することをサポートしていますが, numpy.ndarray を使用することで,より優れた,よりpythonicな代替手段があります.
PyVistaでのNumPyの利用#
NumPy ポイントの配列を作ることができます.
>>> import numpy as np
>>> np_points = np.array([[0, 0, 0], [1, 0, 0], [0.5, 0.667, 0]])
>>> np_points
array([[0. , 0. , 0. ],
[1. , 0. , 0. ],
[0.5 , 0.667, 0. ]])
ここでは numpy.ndarray を使用して,PyVista が基礎となる C 配列を VTK に直接 "指し示す" ようにしています.VTKはすでにNumPyからC配列を直接読み込むAPIを持っていますが,VTKはC++で書かれているので,PythonからVTKに転送されるすべてのものは,VTKが処理できるフォーマットである必要があります.
VTKオブジェクトをPyVistaで使用したい場合は,これも可能です.実際, pyvista.wrap() を使用すると,データの numpy ライクな表現を得ることもできます.例えば,次のようになります.
>>> import pyvista
>>> wrapped = pyvista.wrap(vtk_array)
>>> wrapped
pyvista_ndarray([[0. , 0. , 0. ],
[1. , 0. , 0. ],
[0.5 , 0.667, 0. ]])
基礎となるVTK配列をラップする際には,実際にデータの浅いコピーを行うことに注意してください.つまり,基礎となるC配列からのポインタを numpy.ndarray に渡すことで,2つの配列が効率的にリンクされることになります(NumPyの用語では,返される配列は基礎となるVTKデータへのビューとなります).つまり,numpyの配列インデックスを使って配列を変更し,それを "VTK側" で修正させることができるのです.
>>> wrapped[0, 0] = 10
>>> vtk_array.GetValue(0)
10.0
あるいは,VTK配列から値を変更して,それがnumpyのラップ配列に反映されるのを確認することもできます.それでは,値を戻してみましょう.
>>> vtk_array.SetValue(0, 0)
>>> wrapped[0, 0]
np.float64(0.0)
Pythonのリストやタプルの使用#
PyVistaでは,Pythonのシーケンス( list や tuple )の使用をサポートしており,リストのネストを使ってポイントを定義することができます.
>>> points = [[0, 0, 0], [1, 0, 0], [0.5, 0.667, 0]]
メッシュを作成するために PolyData のコンテキストで使用された場合,このリストは自動的にNumPyを使ってラップされ,VTKに渡されます.これにより,ループのオーバーヘッドを回避しつつ,ネイティブのpythonクラスを使用することができます.
最後に,この3つのオブジェクトをPyVistaのジオメトリクラスでどのように使うかを説明します.ここでは,3つの点だけを含む単純なポイントメッシュを作成します.
>>> from_vtk = pyvista.PolyData(vtk_array)
>>> from_np = pyvista.PolyData(np_points)
>>> from_list = pyvista.PolyData(points)
これらのポイントメッシュはすべて3つのポイントを含んでおり,実質的には同じものです. pyvista.pyvista_ndarray として表現されているメッシュから,基礎となるポイント配列にアクセスしてこれを示しましょう.
>>> from_vtk.points
pyvista_ndarray([[0. , 0. , 0. ],
[1. , 0. , 0. ],
[0.5 , 0.667, 0. ]])
そして,これらがすべて同一であることを示します
>>> assert np.array_equal(from_vtk.points, from_np.points)
>>> assert np.array_equal(from_vtk.points, from_list.points)
>>> assert np.array_equal(from_np.points, from_list.points)
最後に,PyVistaの pyvista.plot() メソッドを使って,この(非常に)シンプルな例をプロットしてみましょう.ここでは,全体の流れがわかるように例を挙げて説明します.
>>> import pyvista
>>> points = [[0, 0, 0], [1, 0, 0], [0.5, 0.667, 0]]
>>> mesh = pyvista.PolyData(points)
>>> mesh.plot(show_bounds=True, cpos='xy', point_size=20)
PyVistaのデータクラスと属性については後ほど説明しますが,ここでは点だけを含むシンプルなジオメトリを作成する方法を紹介します.サーフェスを作成するには,ジオメトリの接続性を指定する必要がありますが,そのためにはこのサーフェスのセル(または面)を指定する必要があります.
PyVistaにおけるジオメトリとメッシュの接続性/トポロジー#
先ほどの例では, "メッシュ" を切断された3つの点として定義しました.これは "点群" を表現するのには便利ですが,サーフェイスを作成したい場合は,メッシュの接続性を記述する必要があります.そのためには,先ほど定義したのと同じ順番で3つの点からなる1つのセルを定義しましょう.
>>> cells = [3, 0, 1, 2]
注釈
VTKに面が3つの要素,この場合は,3つの点によって記述されることを伝えるために,先頭に 3 を挿入しなければならなかったことを確認しください.私たちの PolyData の中では,VTKは面が常に3つの点を含むことを想定していないので,私たちはそれを定義しなければなりません. これにより,セルあたりの点の数を(自由に)定義できるという柔軟性が生まれます.
注釈
すべてのセルタイプは,同じ接続配列形式に従っています:
[Number of points, Point 1, Point 2, ...]
ただし, polyhedron タイプは,セルの各面を定義する必要があります.このタイプのフォーマットは以下の通りです.
[Number of elements, Number of faces, Face1NPoints, Point1, Point2, ..., PointN, Face2NPoints, ...].
ここで number of elements は,このセルを記述する配列の要素の総数を表します.
これで,単一の3角形を含む PolyData のインスタンスを組み立てるために必要なすべての要素が揃いました.これを実現するには,単に points と cells を PolyData のコンストラクタに与えればよいのです.表現から,このジオメトリには3つのポイントと1つのセルが含まれていることがわかります.
>>> mesh = pyvista.PolyData(points, cells)
>>> mesh
| PolyData | Information |
|---|---|
| N Cells | 1 |
| N Points | 3 |
| N Strips | 0 |
| X Bounds | 0.000e+00, 1.000e+00 |
| Y Bounds | 0.000e+00, 6.670e-01 |
| Z Bounds | 0.000e+00, 0.000e+00 |
| N Arrays | 0 |
これもプロットしてみましょう.
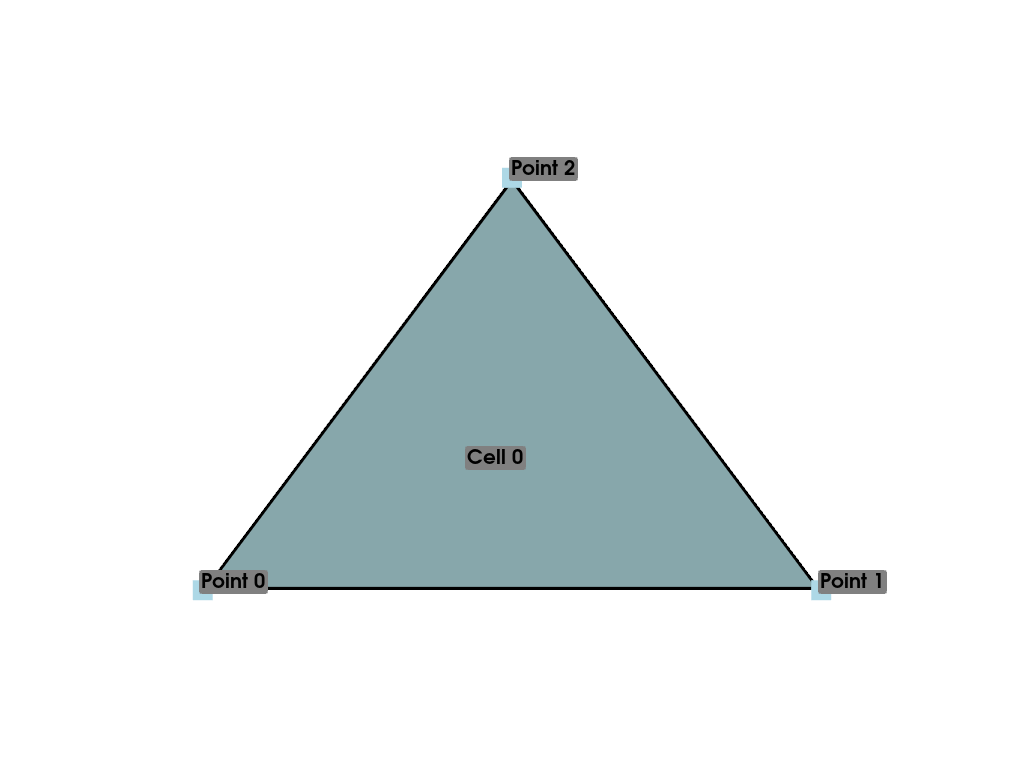
>>> mesh = pyvista.PolyData(points, [3, 0, 1, 2])
>>> mesh.plot(cpos='xy', show_edges=True)

ついでに,このメッシュを説明するために,このプロットにアノテーションをつけてみましょう.
>>> pl = pyvista.Plotter()
>>> pl.add_mesh(mesh, show_edges=True, line_width=5)
>>> label_coords = mesh.points + [0, 0, 0.01]
>>> pl.add_point_labels(
... label_coords,
... [f'Point {i}' for i in range(3)],
... font_size=20,
... point_size=20,
... )
>>> pl.add_point_labels([0.43, 0.2, 0], ['Cell 0'], font_size=20)
>>> pl.camera_position = 'xy'
>>> pl.show()
点の接続性に基づいてポリゴンが作成される様子がよくわかります.
このインスタンスには,メッシュの基礎データにアクセスするためのいくつかの属性があります.例えば,メッシュのポイントにアクセスしたり,変更したりしたい場合は,単純に points でpoints属性にアクセスすることができます.
>>> mesh.points
pyvista_ndarray([[0. , 0. , 0. ],
[1. , 0. , 0. ],
[0.5 , 0.667, 0. ]])
接続性は, faces 属性からもアクセスできます.
>>> mesh.faces
array([3, 0, 1, 2])
あるいは,単純にメッシュの表現を得ることができます
>>> mesh
| PolyData | Information |
|---|---|
| N Cells | 1 |
| N Points | 3 |
| N Strips | 0 |
| X Bounds | 0.000e+00, 1.000e+00 |
| Y Bounds | 0.000e+00, 6.670e-01 |
| Z Bounds | 0.000e+00, 0.000e+00 |
| N Arrays | 0 |
この表現では,次のようになります.
これはVTKからの出力とは大きく異なります. 2つの表現方法の比較については, オブジェクトの表現 を参照してください.
このメッシュは,ジオメトリのみで構成されているため,データ配列を含みません.これは,メッシュのジオメトリだけをプロットするのに便利ですが,データセットにはジオメトリ以外のものが含まれていることがよくあります. 例えば
変化する磁界から計算される電界
動脈を流れる血流のベクトル場
構造用有限要素法による表面応力の解析
地球物理学から見た鉱床
ベクトル場や表面データとしての気象パターン.
これらのデータセットはそれぞれ別のジオメトリクラスとして表現されますが,いずれもジオメトリ内の特定の場所でデータの値を説明するポイント,セル,またはフィールドデータを含んでいます.
データアレイ#
各 DataSet には,基礎となる数値データへのアクセスを可能にする属性が含まれています. この数値データは points やセルに関連付けられている場合もあれば,ポイントやセルには関連付けられておらず,一般的なメッシュに関連付けられている場合もあります.
PyVistaでのデータ配列を説明するために,まず先ほどの例よりも少し複雑なメッシュを作ってみましょう. ここでは,まず ImageData から始めて, cast_to_unstructured_grid() で UnstructuredGrid にキャストすることで,4つのアイソメトリックなセルを含む単純なメッシュを作成します.
>>> grid = pyvista.ImageData(dimensions=(3, 3, 1))
>>> ugrid = grid.cast_to_unstructured_grid()
>>> ugrid
| UnstructuredGrid | Information |
|---|---|
| N Cells | 4 |
| N Points | 9 |
| X Bounds | 0.000e+00, 2.000e+00 |
| Y Bounds | 0.000e+00, 2.000e+00 |
| Z Bounds | 0.000e+00, 0.000e+00 |
| N Arrays | 0 |
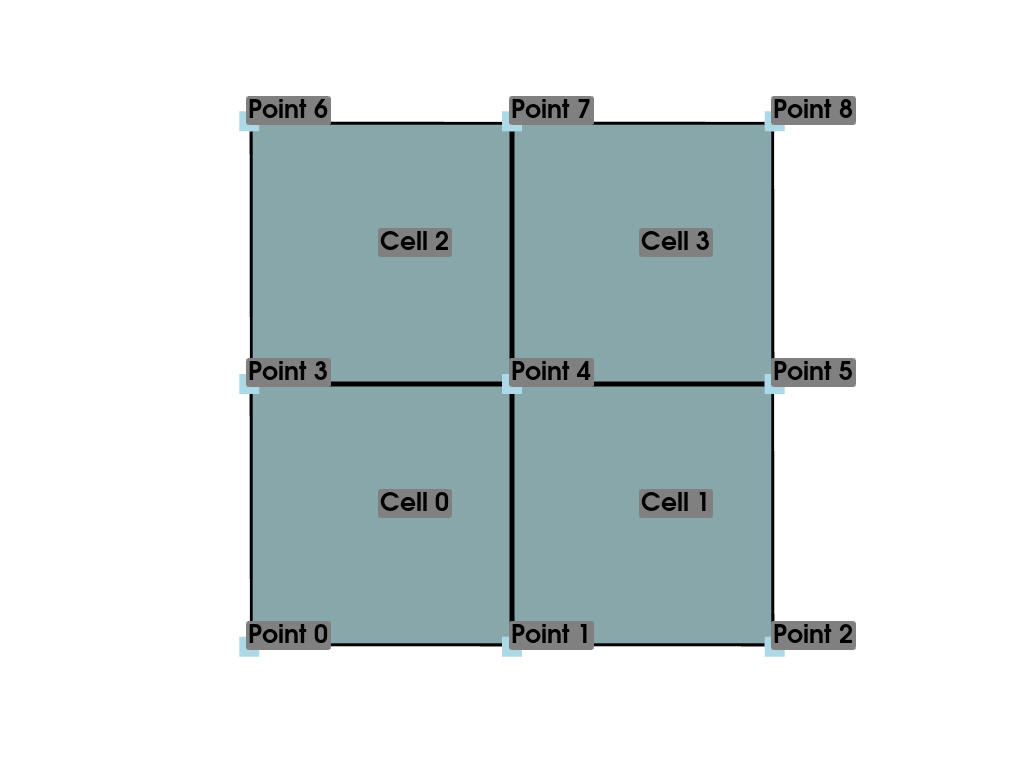
また,この基本的なメッシュをプロットしてみましょう.
>>> pl = pyvista.Plotter()
>>> pl.add_mesh(ugrid, show_edges=True, line_width=5)
>>> label_coords = ugrid.points + [0, 0, 0.02]
>>> point_labels = [f'Point {i}' for i in range(ugrid.n_points)]
>>> pl.add_point_labels(
... label_coords, point_labels, font_size=25, point_size=20
... )
>>> cell_labels = [f'Cell {i}' for i in range(ugrid.n_cells)]
>>> pl.add_point_labels(ugrid.cell_centers(), cell_labels, font_size=25)
>>> pl.camera_position = 'xy'
>>> pl.show()
さて,シンプルなメッシュができあがったところで,データの割り当てを始めましょう. メッシュに関連付けられるデータには,主にスカラーデータとベクトルデータの2種類があります.スカラーデータとは,単一または複数コンポーネントのデータで,方向性がなく,温度などの値や,複数コンポーネントのデータの場合はRGBA値などを含みます.ベクトルデータは,大きさと方向性を持ち,1つのデータポイントに3つの成分を含む配列として表現されます.
プロットする際には,スカラーデータを簡単に表示することができますが,このデータはポイントまたはセルに "関連付け" られている必要があります. 例えば,サンプルのメッシュのセルに値を割り当てたい場合,メッシュの cell_data 属性にアクセスすることで実現できます.
セルデータ#
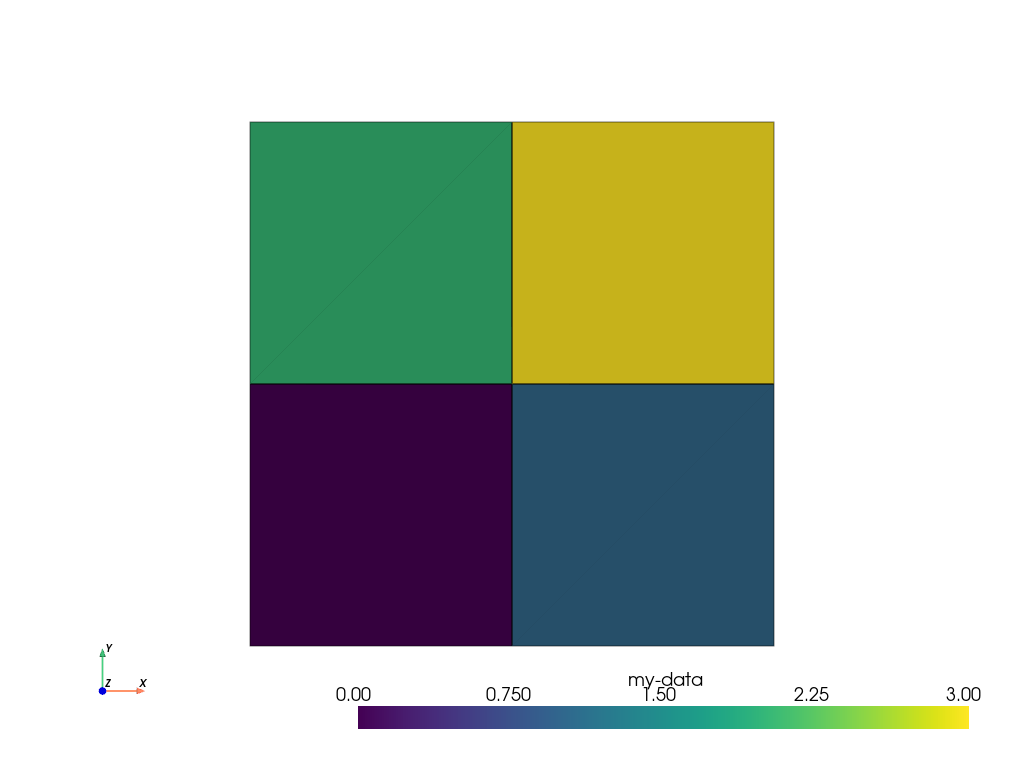
DataSet にスカラーデータを追加する最も簡単な方法は, [] 演算子を使うことです.上の例を続けて,各セルに1つの整数を割り当ててみましょう. これにはPythonの list を使い, UnstructuredGrid のセル数と同じ長さにすることができます.また,もっと単純な例として,適切な長さの range を使用することもできます. ここでは,レンジを作成して cell_data に追加し, [] 演算子を使ってアクセスしています.
>>> simple_range = range(ugrid.n_cells)
>>> ugrid.cell_data['my-data'] = simple_range
>>> ugrid.cell_data['my-data']
pyvista_ndarray([0, 1, 2, 3])
どのように pyvista.pyvista_ndarray が返されるかに注目してください. VTKはC言語の配列を必要とするので,PyVistaは内部的にすべての入力をC言語の配列にラップまたは変換します. そして,これを次のようにしてプロットします.
>>> ugrid.plot(cpos='xy', show_edges=True)
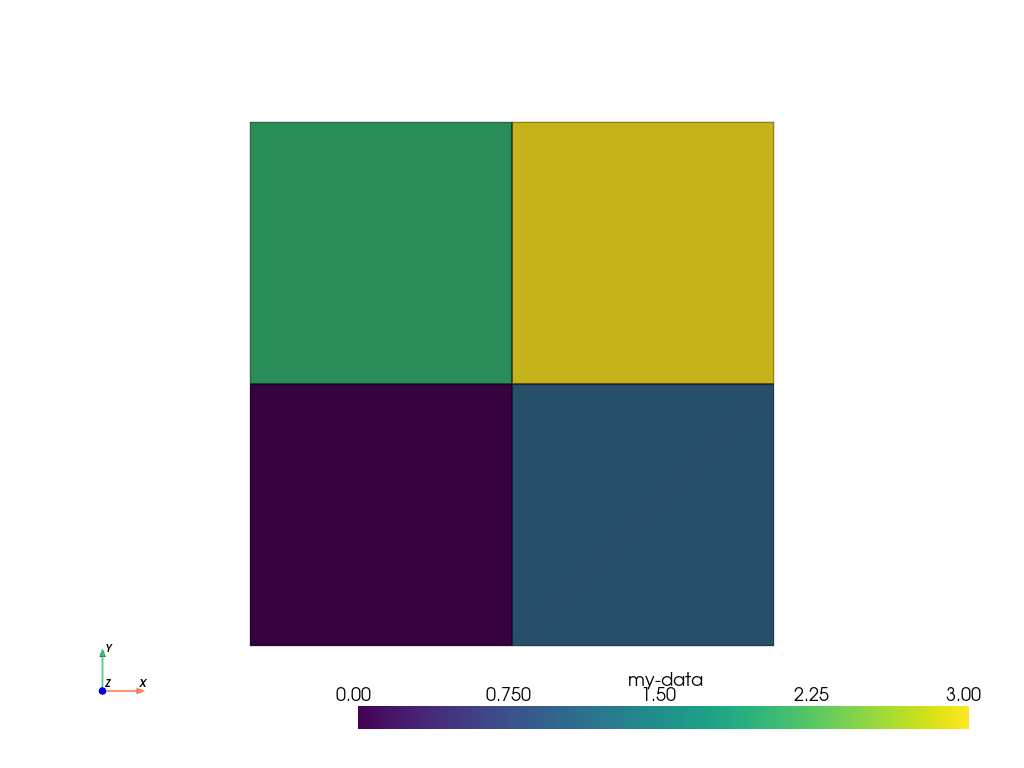
[] 演算子が自動的にアクティブなスカラーを設定するので,どのセルデータをプロットするかを指定する必要がないことに注目してください.
>>> ugrid.cell_data
pyvista DataSetAttributes
Association : CELL
Active Scalars : my-data
Active Vectors : None
Active Texture : None
Active Normals : None
Contains arrays :
my-data int64 (4,) SCALARS
また,どのセルにどのスカラーが割り当てられているかを示すために,プロットにラベルを追加することもできます. 割り当てられたスカラーと同じ順番になっていることに注目してください.
>>> pl = pyvista.Plotter()
>>> pl.add_mesh(ugrid, show_edges=True, line_width=5)
>>> cell_labels = [f'Cell {i}' for i in range(ugrid.n_cells)]
>>> pl.add_point_labels(ugrid.cell_centers(), cell_labels, font_size=25)
>>> pl.camera_position = 'xy'
>>> pl.show()
[] 演算子を使って DataSet にセルデータを割り当て続けることができますが,新しいアレイをアクティブなアレイにしたくない場合は, set_array() を使って追加することができます.
>>> data = np.linspace(0, 1, ugrid.n_cells)
>>> ugrid.cell_data.set_array(data, 'my-cell-data')
>>> ugrid.cell_data
pyvista DataSetAttributes
Association : CELL
Active Scalars : my-data
Active Vectors : None
Active Texture : None
Active Normals : None
Contains arrays :
my-data int64 (4,) SCALARS
my-cell-data float64 (4,)
これで ugrid には2つの配列が入り,そのうちの1つが "アクティブな" スカラーとなります. このアクティブなスカラーのセットは, add_mesh() や pyvista.plot() で scalars が設定されていない場合に,自動的にプロットされるものです. これにより,データセットに関連付けられた多くのセルアレイを持ち,どのセルアレイがデフォルトでアクティブなセルスカラーとしてプロットされるかを追跡することが可能になります.
また,アクティブなスカラーは active_scalars でアクセスでき,アクティブなスカラー配列の名前は active_scalars_name でアクセスまたは設定することができます.
>>> ugrid.cell_data.active_scalars_name = 'my-cell-data'
>>> ugrid.cell_data
pyvista DataSetAttributes
Association : CELL
Active Scalars : my-cell-data
Active Vectors : None
Active Texture : None
Active Normals : None
Contains arrays :
my-data int64 (4,)
my-cell-data float64 (4,) SCALARS
ポイントデータ#
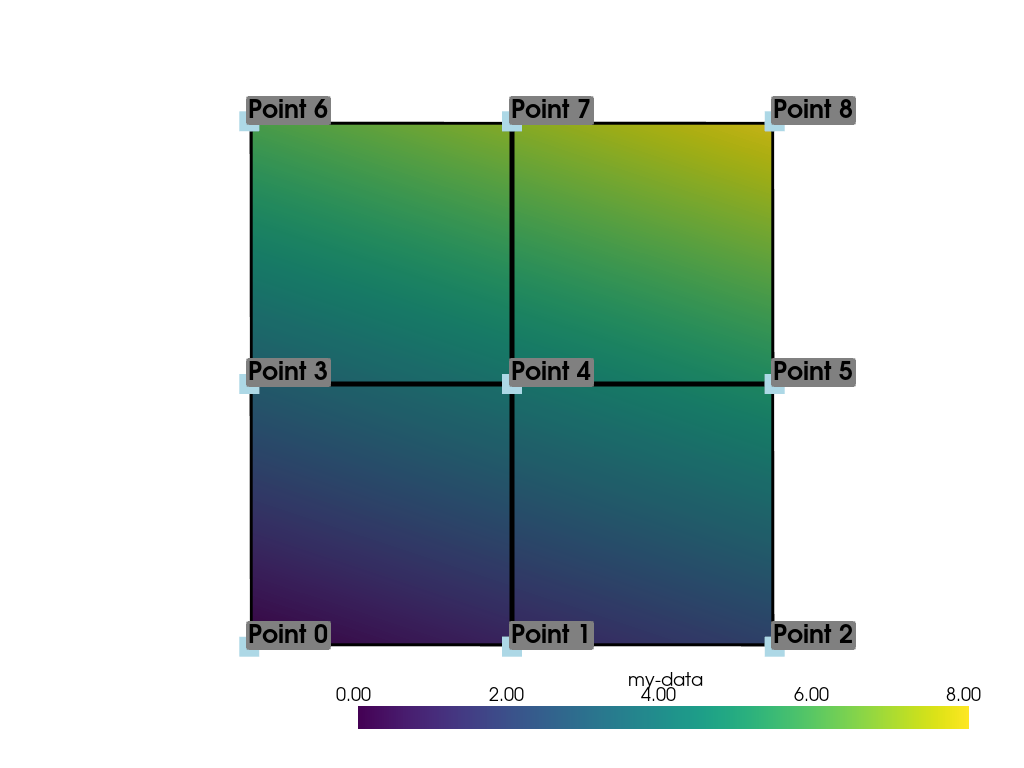
データは セルデータ と同様の方法でポイントに関連付けることができます. point_data 属性を使うと, DataSet のポイントにポイントデータを関連付けることができます. ここでは, [] 演算子を使って,単純なリストをポイントに関連付けることにします.
>>> simple_list = list(range(ugrid.n_points))
>>> ugrid.point_data['my-data'] = simple_list
>>> ugrid.point_data['my-data']
pyvista_ndarray([0, 1, 2, 3, 4, 5, 6, 7, 8])
繰り返しになりますが,これらの値は, [] 演算子を用いることで,デフォルトで点群のアクティブなスカラーとなります.
>>> ugrid.point_data
pyvista DataSetAttributes
Association : POINT
Active Scalars : my-data
Active Vectors : None
Active Texture : None
Active Normals : None
Contains arrays :
my-data int64 (9,) SCALARS
ポイントデータをプロットしてみましょう. 各ポイントにはスカラー値が割り当てられており,それがセル全体を補間して,最も低い値の Point 0 から最も高い値の Point 8 までの間の滑らかなカラーマップを作成しています.
>>> pl = pyvista.Plotter()
>>> pl.add_mesh(ugrid, show_edges=True, line_width=5)
>>> label_coords = ugrid.points + [0, 0, 0.02]
>>> point_labels = [f'Point {i}' for i in range(ugrid.n_points)]
>>> pl.add_point_labels(
... label_coords, point_labels, font_size=25, point_size=20
... )
>>> pl.camera_position = 'xy'
>>> pl.show()
また, セルデータ と同様に, set_array() を使って, point_data に複数の配列を割り当てることができます.
>>> data = np.linspace(0, 1, ugrid.n_points)
>>> ugrid.point_data.set_array(data, 'my-point-data')
>>> ugrid.point_data
pyvista DataSetAttributes
Association : POINT
Active Scalars : my-data
Active Vectors : None
Active Texture : None
Active Normals : None
Contains arrays :
my-data int64 (9,) SCALARS
my-point-data float64 (9,)
ここでも,ポイントデータには2つの配列が関連付けられており,1つだけが "アクティブ" なスカラー配列となっています. また,アクティブなスカラー配列の名前は, active_scalars_name でアクセスまたは設定することができます.
>>> ugrid.point_data.active_scalars_name = 'my-point-data'
>>> ugrid.point_data
pyvista DataSetAttributes
Association : POINT
Active Scalars : my-point-data
Active Vectors : None
Active Texture : None
Active Normals : None
Contains arrays :
my-data int64 (9,)
my-point-data float64 (9,) SCALARS
データセットアクティブスカラー#
前節に引き続き,今回の ugrid データセットには,ポイントデータとセルデータの両方が含まれています.
>>> ugrid.point_data
pyvista DataSetAttributes
Association : POINT
Active Scalars : my-point-data
Active Vectors : None
Active Texture : None
Active Normals : None
Contains arrays :
my-data int64 (9,)
my-point-data float64 (9,) SCALARS
>>> ugrid.cell_data
pyvista DataSetAttributes
Association : CELL
Active Scalars : my-cell-data
Active Vectors : None
Active Texture : None
Active Normals : None
Contains arrays :
my-data int64 (4,)
my-cell-data float64 (4,) SCALARS
(ポイントデータにもセルデータにも)アクティブなスカラーがありますが,データセットレベルでは1種類のスカラーしか "アクティブ" にできません. このデータは active_scalars_info から得ることができます.
>>> ugrid.active_scalars_info
ActiveArrayInfoTuple(association=<FieldAssociation.POINT: 0>, name='my-point-data')
アクティブなスカラーはデフォルトではポイントスカラーであることに注意してください. これは set_active_scalars() でアクティブなスカラーを設定することで変更することができます. アクティブなスカラーを設定したいときに,ポイントデータとセルデータの両方に同じ名前の配列がある場合は, preference を指定しなければならないことに注意してください.
>>> ugrid.set_active_scalars('my-data', preference='cell')
>>> ugrid.active_scalars_info
ActiveArrayInfoTuple(association=<FieldAssociation.CELL: 1>, name='my-data')
これは, add_mesh() や pyvista.plot() の preference パラメータを使用して,プロットする際に設定することもできます.
フィールドデータ#
フィールド配列は, point_data や cell_data とは異なり, DataSet のジオメトリとは関連付けられていません.つまり,フィールドデータをアクティブなスカラーやベクターとして指定することはできませんが,これを使って任意の形状の配列を "添付" することができます. フィールドデータに文字列配列を追加することもできます.
>>> ugrid.field_data['my-field-data'] = ['hello', 'world']
>>> ugrid.field_data['my-field-data']
pyvista_ndarray(['hello', 'world'], dtype='<U5')
なお,フィールドデータは自動的にVTK Cスタイルの配列に転送され,numpyのデータ形式で表現されます.
現在のフィールドデータをリストアップする際には,associationが "NONE "であることに注意してください.
>>> ugrid.field_data
pyvista DataSetAttributes
Association : NONE
Contains arrays :
my-field-data <U5 (2,)
これは,データがポイントやセルに関連付けられていないためであり,フィールドデータがセルやポイントの数と一致することは期待できないため,そうすることはできません. そのため,プロットすることもできません.
ベクトル,テクスチャコード,および法線の属性#
セルとポイントの両方のデータは, active_scalars に加えて,以下の "特別な" 属性を保存することができます.
アクティブな法線#
active_normals の配列は,メッシュのローカルな法線方向を指定する特別な配列です.物理ベースのレンダリングの作成,Phong補間を用いたスムーズなシェーディングのレンダリング,スカラーによるワープなどに使用されます. もし, smooth_shading=True や pbr=True を用いてプロットする際に,この配列が設定されていない場合は,計算されます.
アクティブテクスチャの座標#
active_t_coords の配列は,テクスチャのレンダリングに使用されます. この配列を使った例については, テクスチャを適用する を参照してください.
アクティブベクター#
active_vectors は,大きさと方向(具体的には,3つの成分)を持つ量を含む配列です. 例えば,様々な座標における風速を含むベクトルフィールドです. これは active_scalars とは異なります.スカラーはいくつかの成分を含んでいても,(RGBデータの場合のように)無指向性であることが期待されます.
VTKでは, transform() フィルタを使用して変換を行う際に,ベクトルはスカラーとは異なる扱いになります. スカラー配列とは異なり,ベクトル配列は方向を持つ量を表すため,ジオメトリと一緒に変換されます.
注釈
VTKでは,1つの "アクティブ" なベクトルしか許可しません.変換したい複数のベクトル配列がある場合には, transform() で transform_all_input_vectors=True を設定してください. これは,3つのコンポーネントを持つ配列を変換するので,RGB配列のような複数コンポーネントのスカラー配列は,変換後に破棄しなければならないことに注意してください.