pyvista.DataSetFilters.compute_derivative#
- DataSetFilters.compute_derivative(
- scalars: str | None = None,
- gradient: bool | str = True,
- divergence: bool | str = False,
- vorticity: bool | str = False,
- qcriterion: bool | str = False,
- faster: bool = False,
- preference: Literal['point', 'cell'] = 'point',
- progress_bar: bool = False,
点/セル スカラーフィールドの派生ベースの量を計算します.
vtkGradientFilterを利用して,選択された点またはセルスカラー場の勾配,発散,渦度,およびQ基準などの微分ベースの量を計算する.- パラメータ:
- scalars
str,optional 派生量を計算するときに使用するスカラー配列の文字列名.デフォルトでは,データセット内のアクティブなスカラーが使用されます.
- gradientbool |
str, default:True 勾配を計算します.文字列を渡すと,その文字列が配列名として使用されます.それ以外の場合,配列名は
'gradient'になります.デフォルトはTrue- divergencebool |
str,optional 発散を計算する.文字列を渡すと,その文字列が配列名として使用されます.それ以外の場合,デフォルトの配列名は
'divergence'になります.- vorticitybool |
str,optional 速度を計算します.文字列を渡すと,その文字列が配列名として使用されます.それ以外の場合,デフォルトの配列名は
'vorticity'になります.- qcriterionbool |
str,optional Q-criterionを計算する.文字列を渡すと,その文字列が配列名として使用されます.それ以外の場合,デフォルトの配列名は
'qcriterion'になります.- fasterbool, default:
False 微分量の計算に高速アルゴリズムを使用します.結果の精度が低くなり,導関数の計算が少なくなるため,計算速度が向上します.エラーは出力のスムージングを特徴とし,場合によっては境界でエラーが発生します.DataSetが
pyvista.UnstructuredGridでない場合,オプションは無効です.- preference
str, default: "point" データ型の環境設定.
'point'か'cell'のどちらかです.- progress_barbool, default:
False 進行状況を示す進行状況バーを表示します.
- scalars
- 戻り値:
pyvista.DataSet導関数を計算したデータセット
例
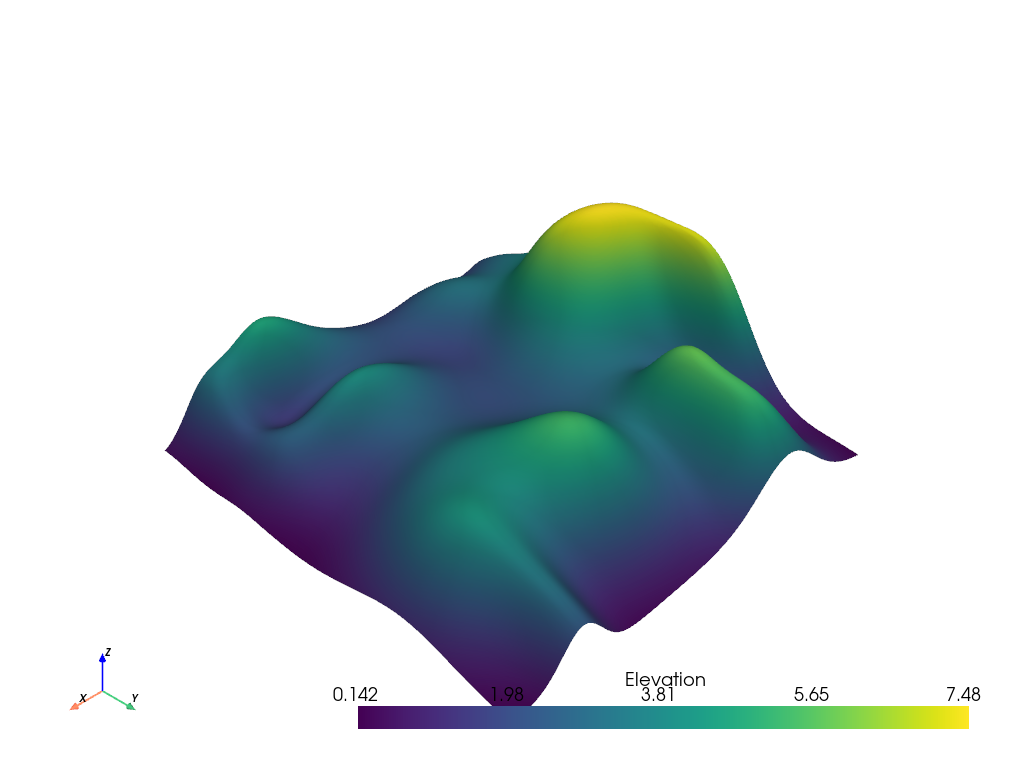
まず,ランダムな丘のデータセットをアクティブな標高スカラーでプロットします. これらのスカラーは,微分の計算に使用されます.
>>> from pyvista import examples >>> hills = examples.load_random_hills() >>> hills.plot(smooth_shading=True)
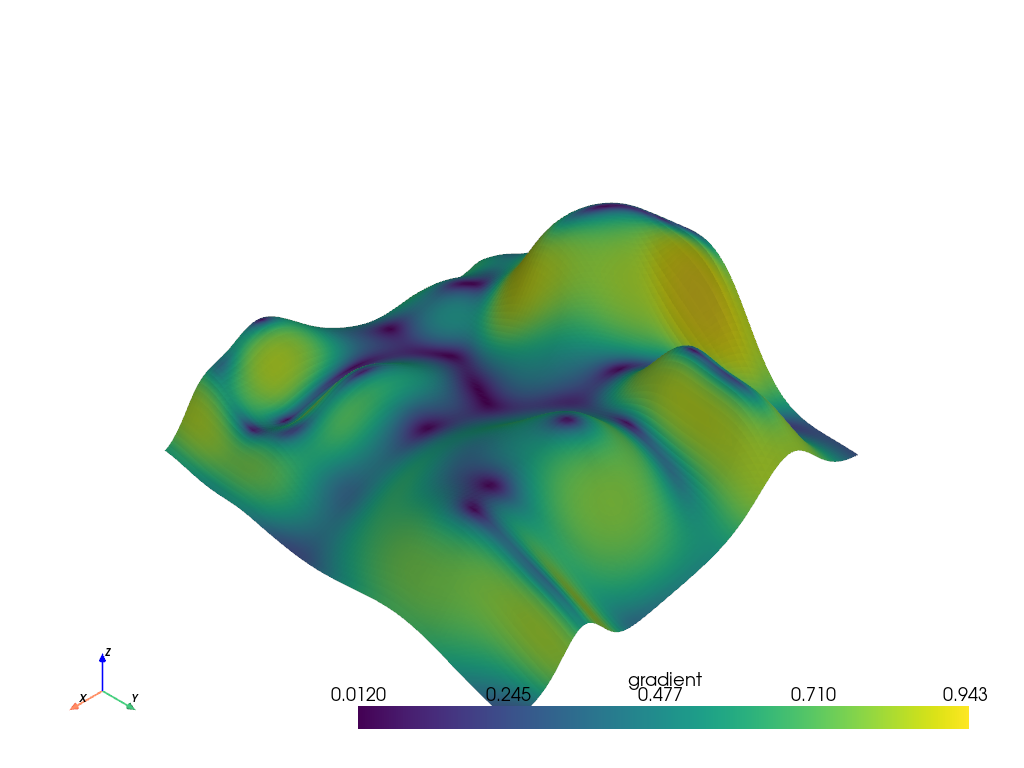
アクティブなスカラーの勾配を計算し,プロットします.
>>> from pyvista import examples >>> hills = examples.load_random_hills() >>> deriv = hills.compute_derivative() >>> deriv.plot(scalars='gradient')
このフィルターを使用したその他の例については, フィールドの勾配を計算する を参照してください.