pyvista.DataSetFilters.sample#
- DataSetFilters.sample(target, tolerance=None, pass_cell_data=True, pass_point_data=True, categorical=False, progress_bar=False, locator=None, pass_field_data=True, mark_blank=True, snap_to_closest_point=False)[ソース]#
渡されたメッシュからこのメッシュに配列データをリサンプルします.
mesh1.sample(mesh2) では, mesh2 の配列が mesh1 の点にサンプリングされます.この関数はセルを囲むように補間します. :function`pyvista.DataSetFilters.interpolate` 関数は,近傍の点に対して距離の重み付けを行います. セルのトポロジーがある場合は,通常 sample を使用します.
点データ 'vtkValidPointMask' には,その点がサンプリングできたかどうかが格納されます.値が1であればサンプリング成功,0であれば失敗を意味します.
これは
vtk.vtkResampleWithDataSetを使います.- パラメータ:
- target
pyvista.DataSet サンプリング元のvtkデータオブジェクトと,このオブジェクトからのセル配列は,
datasetメッシュのノードにサンプリングされます.- tolerance
float,optional ソース内のポイントが入力のセル内にあるかどうかを計算するために使用される許容値です.指定しない場合,公差は自動的に生成されます.
- pass_cell_databool, default:
True ソースメッシュのオリジナルのセルデータ配列を保持する.
- pass_point_databool, default:
True ソースメッシュのオリジナルのポイントデータ配列を保持する.
- categoricalbool, default:
False ソースポイントデータをカテゴリとして扱うかどうかをコントロールします.データがカテゴリー化されている場合,得られるデータは,最近傍補間スキームによって決定されます.
- progress_barbool, default:
False 進行状況を示す進行状況バーを表示します.
- locatorvtkAbstractCellLocator または python:str, optional
FindCell()操作を実行するセルロケータのプロトタイプ.デフォルトでは,DataSetのFindCellメソッドを使用します.vtkのセルロケータに対応する有効な文字列は以下の通りです'cell' - vtkCellLocator
'cell_tree' - vtkCellTreeLocator
'obb_tree' - vtkOBBTree
'static_cell' - vtkStaticCellLocator
- pass_field_databool, default:
True ソースメッシュのオリジナルのフィールドデータ配列を保持します.
- mark_blankbool, default:
True "vtkGhostType" の空白ポイントとセルをマークするかどうか.
- snap_to_closest_pointbool, default:
False セルが見つからない場合,最も近いポイントにスナップするかどうか.頂点セルを持つデータからサンプリングする際に便利です.vtk >=9.3.0が必要です.
バージョン 0.43 で追加.
- target
- 戻り値:
pyvista.DataSetリサンプリングされたデータを含みますデータセットです.
例
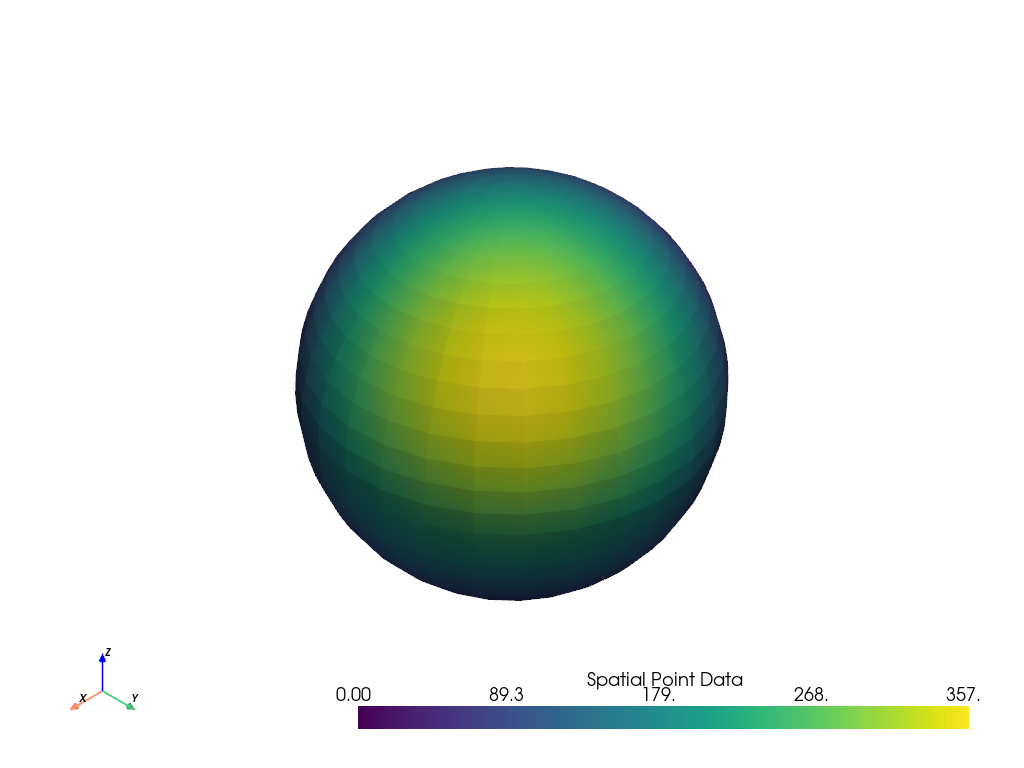
他のデータセットのデータを球体に再サンプルします.
>>> import pyvista as pv >>> from pyvista import examples >>> mesh = pv.Sphere(center=(4.5, 4.5, 4.5), radius=4.5) >>> data_to_probe = examples.load_uniform() >>> result = mesh.sample(data_to_probe) >>> result.plot(scalars="Spatial Point Data")
(n, 3)形式のnumpy.ndarrayで表現される点の集合からサンプリングする場合,それらを PyVista DataSet に変換する必要があります,例えばまずpyvista.PolyData.>>> import numpy as np >>> points = np.array([[1.5, 5.0, 6.2], [6.7, 4.2, 8.0]]) >>> mesh = pv.PolyData(points) >>> result = mesh.sample(data_to_probe) >>> result["Spatial Point Data"] pyvista_ndarray([ 46.5 , 225.12])
このフィルターを使用したその他の例については, 再サンプリング を参照してください.